앞선 포스트에서 정리하였던 것과 같이 경사하강 알고리즘은 비용함수를 미분하여 경사를 획득하고 이 경사값을 따라 진행해가며 그 값이 수렴할 때까지 반복하는 것입니다.이를 수식으로 표현하면 아래와 같이 요약됩니다.θj:=θj−α∂∂θjJ(θ0,θ1) \theta_j := \theta_j - \alpha \frac{\partial}{\partial \theta_j} J(\theta_0, \theta_1) θj:=θj−α∂θj∂J(θ0,θ1)선형회귀의 경우에 대해서 구체적으로 이를 적용해 보도록 하겠습니다.이를 위하여 비용함수와 가설함수를 선형회귀의 비용함수와 가설함수로 교체하도록 합니다.우선 선형회귀의 비용함수는 다음과 같습니다.J(θ0,θ1)=12m∑i=1m(y^i−yi)2=12m∑i=1m(hθ(..
기계학습

경사하강법의 동작에 대해서 살펴보기 위하여 문제를 간단히 해보도록 합니다.하나의 입력 파라메터 θ1\theta_1θ1 만을 고려한 비용함수를 이용하여 비용하강 알고리즘에 대하여 살펴보겠습니다.하나의 입력 파라메터만을 사용할 경우, 아래의 결과 값이 수렴할 때까지 반복하게 됩니다. θ1:=θ1−αddθ1J(θ1) \theta_1:=\theta_1-\alpha \frac{d}{d\theta_1} J(\theta_1) θ1:=θ1−αdθ1dJ(θ1)위 과정은 비용함수(J(θ)J(\theta)J(θ))의 경사값의 부호(+, -)와 관계 없이 비용함수의 최소값 수렴하게 됩니다. 그 과정은 아래의 그림에 표현되어 있습니다.경사값이 양수일 경우, 새로 갱신되는 θ\thetaθ 값은 이전의 θ\thetaθ..
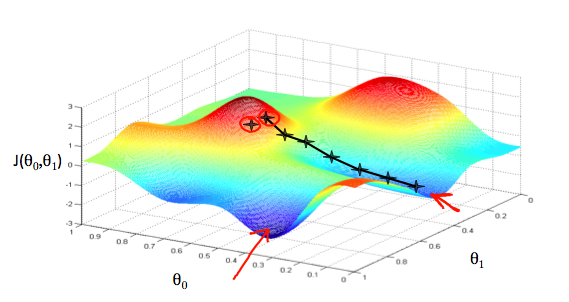
경사하강법 (Gradient Descent) 이제 우리는 가정(모델) 함수를 가지고 있으며, 이것이 얼마나 데이터에 들어맞는지 측정할 방법도 있습니다. 이제 우리는 가정 함수의 파라메터를 추정해야 합니다. 경사하강법은 여기에 사용됩니다.우리가 가정 함수를 θ0\theta_0θ0 와 θ1\theta_1θ1 에 기반한 그래프를 그린다고 해보겠습니다 (실제로 우리는 파라메터 추정의 함수로서 비용 함수를 그래프로 나타냅니다.) . 우리는 x 와 y 자체가 아닌, 우리 가정합수의 파라메터의 범위와 특정 파라메터를 선택했을 때의 비용 결과를 그래프로 나타냅니다.θ0\theta_0θ0 를 x 축에 놓고 θ1\theta_1θ1 을 y 축에 놓고, 비용함수를 z 축에 놓았습니다. 그래프 상의 값은 특정 thet..

모델 표현(Model Representation) 표기법 우선 여기서 앞으로 사용하게 될 표기법을 정의하고 넘어가도록 하겠습니다. x(i)x^{(i)}x(i) : 입력 특징 또는 “입력” 변수 (집의 면적) y(i)y^{(i)}y(i) : “출력” 혹은 목표 변수(집의 가격) (x(i),y(i))(x^{(i)} , y^{(i)})(x(i),y(i)) : 훈련예제 또는 데이터집합 (학습에 사용) (x(i),y(i))(x^{(i)}, y^{(i)})(x(i),y(i)); i=1,…, m : 훈련집합(m 개의 훈련예제) 여기서 윗첨자 “(i)” 는 훈련집합의 인덱스를 의미합니다. 입력변수의 공간을 표현하기 위해서 X 를 사용하고, 출력값의 공간을 표시하기 위해서 Y 를 사용할 것입니다. 이번 예제의 경우는 X..
비지도 학습을 사용하면 우리의 결과가 어떻게 보일지 거의 또는 전혀 모르는 상태에서도 문제에 접근할 수 있습니다. 우리는 변수의 효과를 반드시 알 필요가 없이 데이터로부터 구조를 도출할 수 있습니다.비지도 학습에서는 예측결과에 대한 피드백이 없습니다.예시:클러스터링(Clustering) : 100 가지의 유전자를 모아, 이 유전자를 수명, 위치, 역할 등과 같은 다양한 변수에 의해 어떻게 유사하거나 관련되어 있는지 그룹으로 자동 분류하는 방법을 찾으세요.Non-clustering : "칵테일 파티 알고리즘"은 혼란스러운 환경에서 구조를 찾을 수 있도록 합니다. (즉, 칵테일 파티와 같이 소리가 섞여있는 곳에서 개별 목소리와 음악을 식별해 낼 수 있습니다. )출처 : Coursera - Machine Le..
지도학습 지도학습에서는 입력과 출력 사이에 관계가 있다는 아이디어를 가지고 우리의 올바른 출력이 어떻게 보일 것인가를 이미 알고 있는 데이터 집합이 우리에게 주어집니다. 회귀와 분류 지도학습 문제는 “회기(regression)” 과 “분류(classification)” 문제로 범주화 할 수 있습니다. 회기 문제에서 우리는 결과를 연속적인 출력값으로 예측합니다. 이 말은 우리가 변수들을 연속함수로 맵핑하려고 시도한다는 뜻입니다. 반면 분류 문제에서 우리는 출력을 불연속값으로 예측하려고 합니다. 다른 말로 우리는 입력 변수를 분리된 카테고리에 매핑하려 한다고 할 수 있습니다.예시 1:부동산 시장에서 집의 크기에 관한 데이터가 주어졌을 때, 그것들의 가격을 예측하는 것. 가격은 크기의 함수로 연속적인 출력값을..
두 가지 정의가 제시됩니다. 아서 사무엘(Arthur Samuel)은 “명시적으로 프로그램하지 않고 컴퓨터에게 학습할 수 있는 능력을 주는 것을 연구하는 분야” 라고 했습니다. 이것은 더 오래 되었으며, 비공식적인 정의입니다.톰 미첼(Tom Mitchell)은 좀 더 현대적인 정의로 “과제 T 를 수행할 때의 성능 P가 경험 E를 통해 향상된다면, 컴퓨터 프로그램은 어떤 종류의 과제 T 와 성능 측정 P 와 관련하여 경험 E 로부터 학습한다고 할 수 있다.” 라고 하였습니다예시 : 체커하기E = 많은 체커 게임 수행 경험T = 체커를 하는 것P = 프로그램이 다음 게임에서 승리할 확율일반적으로, 어떻한 머신러닝 문제라도 다음 두 넓은 범위의 카테고리 중 하나로 할당될 수 있습니다.지도학습과 비지도 학습...